
LLM
거대언어모델 (Large Language Model, LLM) 은 쉽게 말해 대용량 언어 모델을 말한다.
🔹대량의 텍스트 데이터를 학습하여 인간처럼 자연어를 이해하고 생성할 수 있는 🤖AI 모델
🔹주로 딥러닝 기술을 기반으로 하며, 수십억 개 이상의 매개변수를 활용하여 텍스트 기반 작업을 수행
특징
🔹 대량의 데이터를 학습하여 높은 수준의 자연어 처리 가능
🔹 문맥(Context)을 이해하고 문장을 생성, 요약, 번역할 수 있음
🔹 Few-shot 및 Zero-shot Learning 지원 (적은 예제만으로도 새로운 작업 수행 가능)
🔹 다양한 애플리케이션 적용 가능 (챗봇, 코드 생성, 자동 번역 등)
자주 사용하는 용어
- LLM은 주로 트랜스포머(Transformer) 기반으로 설계 됨.
- 단어 임베딩: 단어들을 고차원 벡터로 표현하여 각 단어 간의 유사성과 관계를 캡처하는 기술
- 주의 메커니즘: 입력 시퀀스의 다양한 부분에 가중치를 부여하여 모델이 중요한 정보에게 집중할 수 있도록 하는 기술
- Transformer: 주의 메커니즘을 기반으로 한 인코더와 디코더 구조의 신경망 모델로, 길이가 다른 시퀀스를 처리하는 데 탁월한 성능
- Fine-tuning LLMs: 사전 학습된 대규모 언어 모델을 특정 작업에 적용하기 위해 추가 학습하는 과정
- Prompt engineering: 모델에 입력하는 질문이나 명령을 구조화하여 모델의 성능을 향상시키는 과정
- Bias (편향): 모델이 학습 데이터의 불균형이나 잘못된 패턴을 포착하여 실제 세계의 현실과 일치하지 않는 결과를 내놓는 경향
- 해석 가능성: LLM이 가진 복잡성을 극복하고 AI 시스템의 결과와 결정을 이해하고 설명할 수 있는 능력
LLM 작동 방식 및 원리
기본적으로 언어 모델은 통계 모델에서 출발했으며,
LLM은 딥러닝의 방식으로 방대한 양을 사전 학습(Pre-trained)한 전이 학습 (Transfer) 모델이라고 할 수 있다.
LLM은 문장에서 가장 자연스러운 단어 시퀀스를 찾아내는 딥러닝 모델이다.
딥러닝 기술을 사용하여, 문장에서 단어와 구문을 인식하고 이를 연관시켜 언어적 의미를 파악할 수 있다.
이러한 과정에서, LLM은 문법 규칙이나 단어의 사전적 의미와 같은 구체적인 규칙은 따르지 않고,
빈도수나 문법적인 특성 등을 학습하여, 문맥상 올바르게 문장을 생성할 수 있다.
즉, 문장 속에서 이전 단어들이 주어지면 다음 단어를 예측하거나 주어진 단어들 사이에서 가운데 단어를 예측하는 방식으로 작동한다.
이러한 인공 신경망 기반의 언어 모델들은 방대한 양의 데이터를 학습하여, 마치 인간처럼 자연스러운 문장을 생성할 수 있다.
대표적인 방식으로 attention 기법을 활용해 언어 모델의 성능을 크게 향상시킨 Transformer가 있다.

이처럼 LLM을 학습시키는 방법은 대부분 방대한 양의 텍스트 데이터를 딥러닝 알고리즘에 입력하는 것이다.
이때 일반적으로, 먼저 토큰화(tokenization)과 같은 전처리 과정을 거쳐 문자열 데이터를 분리한 다음,
BERT, GPT, GPT-2, GPT-3, T5 등의 base 모델을 사용하여 학습을 진행한다.
LLM의 역사와 주요 모델
언어 모델은 크게 Encoder 기반 / Encoder-Decoder 기반 / Decoder 기반 3가지 구조로 나뉘는데,
최근 주목받고 있는 ChatGPT나 LLaMA 같은 LLM들은 생성형 언어모델로, Decoder 기반 언어 모델들이다.
Decoder 기반 LLM은 또 OpenAI의 GPT 계열과 Meta(구 페이스북)의 LLaMA 계열로 크게 나뉘는 것 같다.
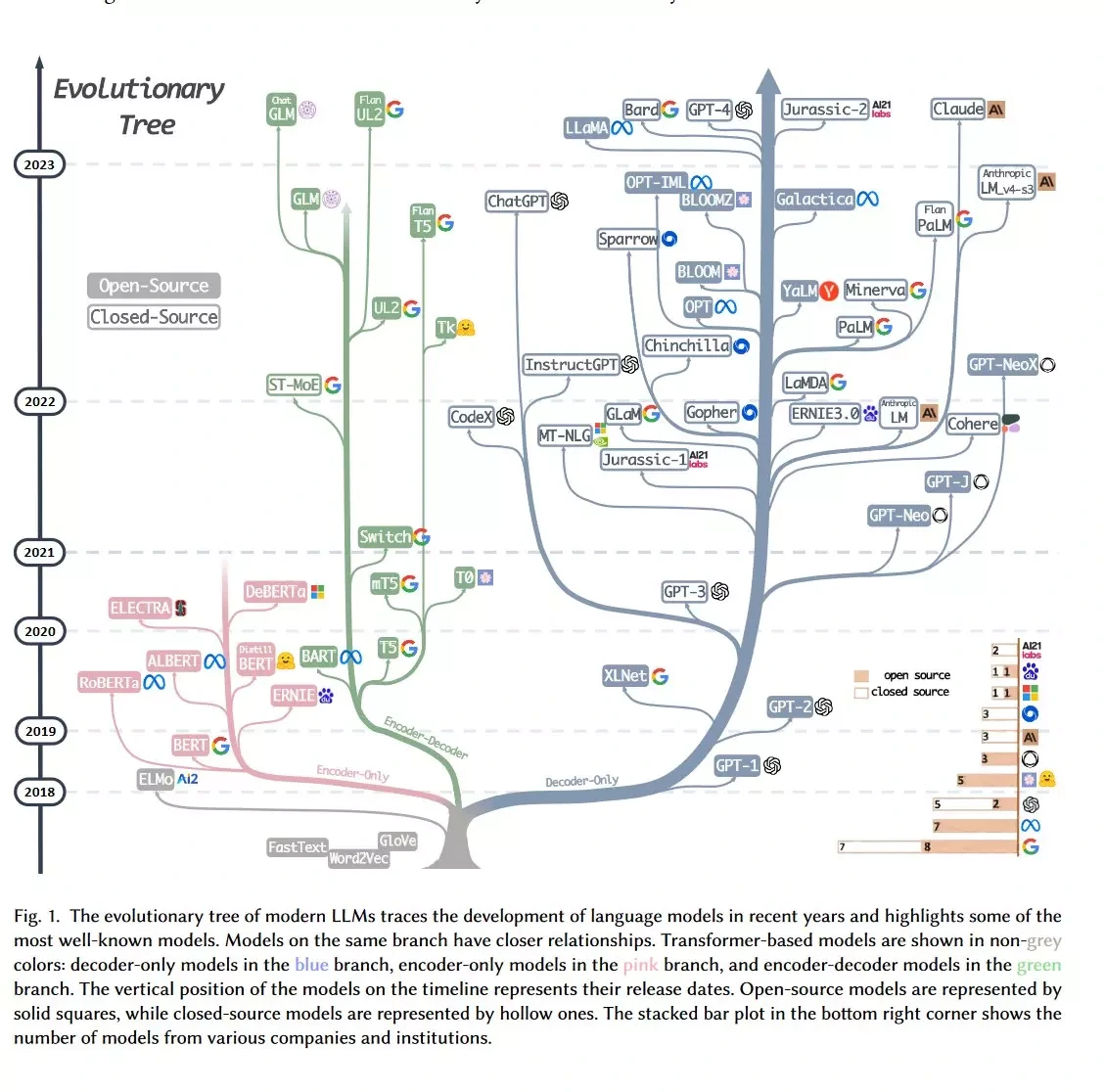
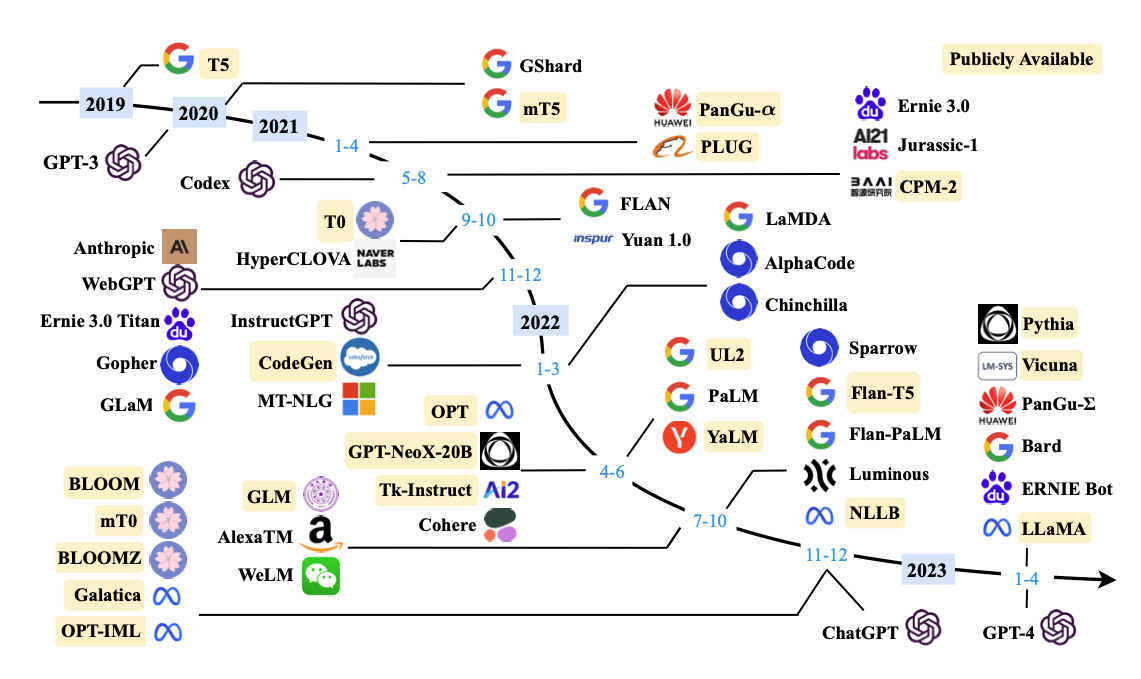
최근 가장 주목 받는 LLM의 핵심 모델은 다음과 같다.
- GPT-3.5 (OpenAI): GPT-3보다 약간의 성능과 안정성을 개선했으며, 광범위한 학습 데이터를 활용해 언어 이해 및 생성 능력을 향상시켜 SOTA를 달성.
- GPT-4 (OpenAI): GPT-3의 후속 모델로, 이전 버전보다 더 큰 모델 크기와 더 정교한 언어 이해와 생성 능력을 갖추고 있음.
- PaLM 2 (Google): Pre-trained Automatic Metrics를 사용한 언어 모델로, 사전 훈련된 언어 모델을 사용하여 기계 번역, 요약, 질문 응답 등의 다양한 NLP 작업에서 성능 평가를 위해 사용됨.
- LlaMA (Meta AI): Language Model Benchmark (LlaMA)에서 개발한 작업 중심 언어 모델로 sota를 달성함. 다양한 자연어 처리 작업을 포함하여 언어 모델의 성능을 평가하고 비교하기 위해 사용됨.
개인적인 생각으로 생성형 LLM의 근본은 GPT이나,
소스코드를 공개하지 않은 OpenAI와 달리 메타는 오픈소스로 공개했기 때문에 활용도가 가장 높은 것은 LLaMA가 아닐까 싶다.
오픈소스 LLM
오픈소스 LLM으로는 다음과 같은 모델들이 공개되어 있다.
- 메타에서 개발한 오픈소스 ‘라마(Llama, Large Language Model Mode AI) 2'
- 뉴아틀라스의 ‘알파카(Alpaca)7B’
- 딥마인드의 ‘쥬라기-1 점보(Jurassic-1 Jumbo)’
- 구글 AI에서 개발한 ‘메가트론-튜링 NLG(Megatron-Turing NLG)’
한국어에 특화된 오픈소스 LLM으로는 튜닙이 배포한 ‘폴리글롯(Polyglot)’이 있다.